Is Big Data all about Dark Data?
So far, my favorite description of Big Data is:
Big Data is when it is cheaper to keep all data than to think about what data you probably need to answer your (business) questions.
Why is this description so attractive? Well, Big Data is primarily a technology, i.e. storing data in a Hadoop File System (HFS) – at least for the most of us. This makes storing data extremely cheap, both in terms of structuring your data (far more expensive in a database) and physically storing it.

But at some point we need to analyze the data, no matter if we stored it “without” much structure in a HFS or with an analysis in mind in a database. In the Big Data case we probably just postponed the process of getting this work done.
Here is where the new buzz word comes into play: “Dark Data Mining”. According to Gartner, Dark Data is data, where we “fail to use for analysis purposes”. And kdnuggest have even a great visualization for the whole problem:
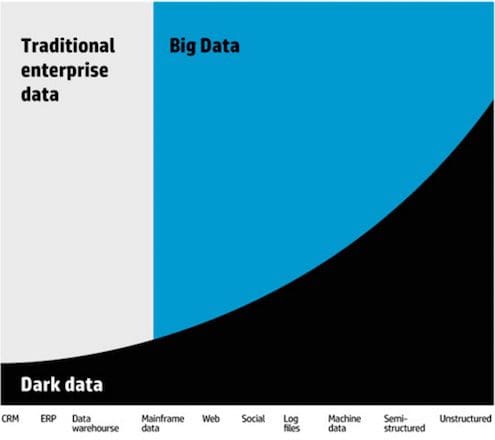
Whereas Kaushik Pal still sees a big business potential within Dark Data, I would look at it from a different perspective.
Dark Data Mining is like coal mining, where you do not separate lignite and spoil during the mining process, but you both put it on the same dump – because it is cheaper – but you start mining for the lignite in the dump once you actually want to use it …

